

A new study from researchers at MIT finds that the performance of the large language models (LLMs) underpinning business automation is advancing steadily but does not yet offer revolutionary excellence across a wide range of economically relevant tasks.
The study sought to understand if the capabilities of the LLMs were more akin to “crashing waves” or “rising tides” along a spectrum tied to task completion thresholds and the level of human intervention required.
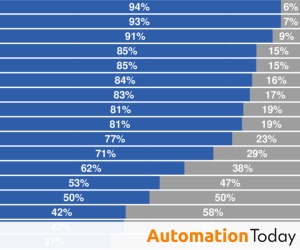
While researchers found that LLMs are already capable of completing a meaningful share of knowledge-based tasks with minimal oversight, performance degrades in scenarios requiring sustained reasoning, contextual judgment, or domain-specific expertise.
But, how good is the work? The study looked at the performance of more than 11,000 text-based tasks by models released between June 2023 and August 2025. By the end of the study period, researchers say AI models were completing in seconds tasks that take humans three to four hours with about a 50 percent success rate. Success, however was defined as work that achieved a “minimally sufficient quality level.”
According to researchers, the rate of progress shown in the study suggests minimally sufficient work will be produced successfully up to 95 percent of the time by 2029.
The report highlights that variability across tasks remains significant, reinforcing the need for human-in-the-loop architectures in enterprise deployments.
“Even when models appear highly capable, their performance is uneven across task types and reliability thresholds,” the researchers wrote in their report. “This variability has important implications for how organizations should integrate AI into real-world workflows.”
For automation vendors and enterprise buyers, the findings underscore a shift away from broad claims of full automation toward more targeted augmentation strategies. The researchers suggest that organizations will see the most immediate value by deploying LLMs in bounded use cases where inputs and outputs are well-defined and error tolerance is manageable.
Overall, the report frames LLMs, in their current state, as incrementally transformative rather than universally disruptive.
